

In a world where technology is constantly evolving, the way we interact with content is also changing. Text-to-speech generator tools have become increasingly popular for their convenience and accessibility, allowing users to convert written text into spoken words effortlessly. As we step into April 2025, let’s take a deep dive into the latest and most powerful text-to-speech generator tools that are making waves in the digital sphere. Whether you’re a content creator, a student looking to enhance your learning experience, or simply curious about the latest tech trends, this blog is your ultimate guide to staying ahead of the curve. So buckle up and get ready to explore the future of text-to-speech technology!
Ad Auris
Ad Auris is a state-of-the-art AI-powered Text-to-speech tool and powerful audio studio that helps writers, bloggers, and publishers convert written content into audio formats. Founded in 2020 in Canada, it offers users the opportunity to access an extensive range of tools to create high-quality audio of any article by copying and pasting its URL or the whole article. By using Ad Auris, users can generate more engagement with their content and expand into new audiences quickly and easily. The interface is easy to use, and it supports three different languages: English, Spanish, and French.


Features
- Premium Voices: Ensures global accessibility and relatability by offering a diverse selection of voices in more than 50 languages and dialects.
- Customizable Audio Player: Enables users to customize the audio player to complement their brand’s visual identity, resulting in a seamless listener experience.
- Scripting Tools: Automatically generates audio-first scripts from written content, which can be refined to achieve the desired audio output.
- Distribution to Podcast Platforms: Facilitates the effortless transfer of audio content to platforms such as YouTube and Spotify, thereby expanding its audience.
- Analytics: Provides comprehensive engagement analytics to assist users in comprehending listener behavior and optimizing their content strategies.
Pricing
- Basic: $288.00 per year.
- Professional: $9600.00 per year.
- Free Plan: Available.


Cartesia AI
Cartesia AI stands out as a real-time multimodal intelligence platform focused on generating natural speech and powering voice applications. At its core, it uses state space models to create high-quality voice outputs with minimal latency. This technology powers everything from customer support automation to gaming characters and content creation. Cartesia AI serves multiple uses through its flexible architecture. The platform excels at voice synthesis tasks and offers deep customization options. Users can modify pitch, speed, emotion, and pronunciation to achieve their desired output. This level of control makes it particularly valuable for applications that need precise voice characteristics.


Features
- Fast Voice Generation: The Sonic Generative Voice API stands as Cartesia AI’s flagship feature. With a time-to-first-audio of just 90ms, it enables rapid voice synthesis for real-time applications. This speed comes from the state space model architecture that processes audio requests instantly.
- Complete Voice Customization: Cartesia AI offers deep control over voice characteristics. Users can adjust pitch, speed, emotion, and pronunciation to match specific requirements. This precise control helps create distinct voice personalities for different use cases.
- On-Device Processing: The platform runs directly on local devices, removing the need to send data to external servers. This architecture provides enhanced privacy and security for sensitive voice applications.
- Multilingual Support: Cartesia AI currently supports 15 languages, including English, German, Spanish, French, Japanese, Chinese, Portuguese, and Italian. The platform can convert voices between different accents and languages while maintaining natural pronunciation.
- Voice Cloning Technology: The platform’s voice cloning feature creates custom voice models from just 5 seconds of audio. Users can scale this capability to handle hours of voice data through fine-tuning options. The system offers two modes: a stable version for consistent output and a high-similarity mode for maximum voice matching.
- Advanced State Space Models: The underlying technology uses state space models that deliver significant technical advantages. These models maintain memory across interactions while using minimal computational resources.
Pricing
- Pro: $5.00 per month.
- Startup: $49.00 per month.
- Scale: $299.00 per month.
- Free Plan: Available.


Deepgram
Deepgram is a speech-to-text (STT) API provided by Deepgram Inc. According to the vendor, this solution accurately converts spoken language into written text with high accuracy, speed, and cost-effectiveness. Deepgram caters to companies of various sizes, offering its speech recognition technology to a wide range of industries and professions. These include contact centers, speech analytics providers, conversational AI developers, media transcription services, podcasters, call centers, media and entertainment companies, customer service teams, sales and marketing professionals, and podcast creators.

Features
- Speech Understanding: The vendor claims that Deepgram’s speech understanding capabilities leverage AI language models to extract key topics and insights from spoken content, providing concise summaries of lengthy files.
- Language Detection: According to the vendor, Deepgram’s language detection feature accurately identifies and transcribes audio in different languages, supporting multilingual applications and enhancing customer interactions.
- Topic Detection: Deepgram’s topic detection feature automatically identifies and labels key topics discussed in audio content, facilitating trend analysis and actionable insights, according to the vendor.
- Captioning and Subtitles: According to the vendor, Deepgram’s transcripts are accurate and support real-time and batch processing, making them suitable for creating accurate and accessible captions and subtitles for media content.
- Custom Model Training: Deepgram’s custom model training feature allows industries with domain-specific jargon or accents to improve accuracy and performance in speech recognition tasks, as stated by the vendor.
- Pure Transcription: Deepgram specializes in handling challenging audio scenarios such as background noise, multiple speakers, and crosstalk, providing accurate and readable transcripts, according to the vendor.
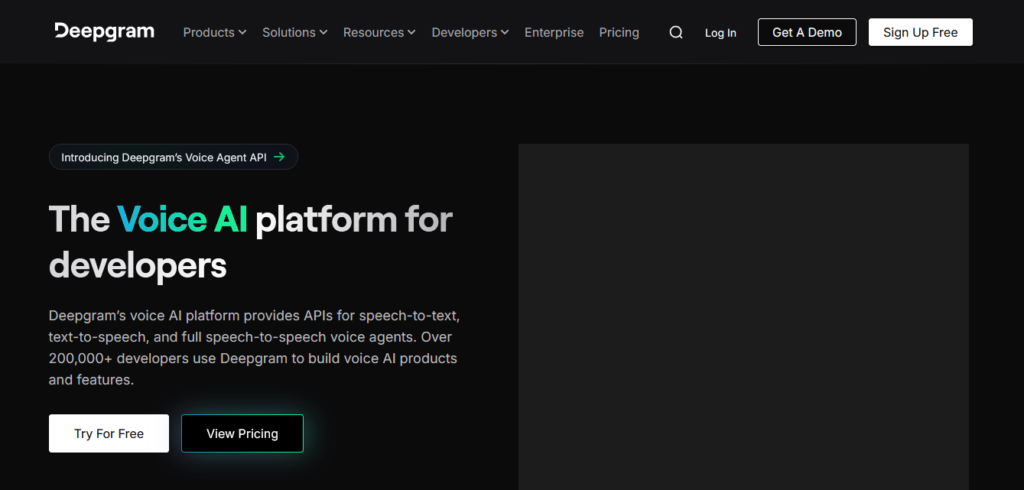
Pricing
- Growth: $4k+ per year.
- Enterprise: $15k+ per year.
- Free Plan: Available.

ElevenLabs
ElevenLabs is an innovative tool designed to revolutionize the way we interact with audio content. At its core, ElevenLabs leverages advanced artificial intelligence to provide high-quality, lifelike voice synthesis. This technology allows users to convert written text into natural-sounding spoken audio, making it an invaluable asset for content creators, educators, and businesses alike. The platform supports a wide range of applications, from audiobook production and podcast creation to voiceovers for educational videos and virtual assistants.

Features
- Real-time voice cloning: Clone a voice from just a few seconds of audio to generate realistic synthetic speech.
- Multi-language support: Offers extensive language capabilities, enabling voice synthesis in numerous global languages.
- API integration: Easily integrate with existing systems using the robust API for seamless automation of voice tasks.
- Custom voice creation: Tailor and create unique voices to suit specific branding or personalization needs.
- High-quality audio output: Produces clear, lifelike audio quality that enhances user engagement and experience.
- Scalable solutions: Designed to handle large-scale deployments, making it suitable for enterprises and developers alike.
Pricing
- Starter: $5.00 per month.
- Creator: $11.00 per month.
- Pro: $99.00 per month.
- Scale: $330.00 per month.
- Business: $1320.00 per month.
- Free Plan: Available.

FreeTTS
FreeTTS is a versatile online tool designed to convert text into spoken words using advanced text-to-speech technology. This user-friendly platform supports multiple languages and voices, allowing users to customize the speech output to fit their needs. Whether you’re looking to enhance digital content, assistive reading, or develop multimedia applications, FreeTTS provides a straightforward solution. The tool is particularly useful for educators, content creators, and developers who require high-quality voice synthesis.
Features
- Multiple language support: Offers text-to-speech services in various languages, enhancing accessibility for global users.
- Simple user interface: Designed for ease of use, allowing users to convert text to speech with minimal effort.
- High-quality voices: Provides a selection of natural and clear voices, improving the listening experience.
- No installation required: Accessible directly via web, eliminating the need for software downloads and installations.
- Free to use: Allows users to convert text to speech without any cost, making it accessible to everyone.
- API availability: Offers an API for developers to integrate text-to-speech capabilities into their applications.
Pricing
- Starter Plan: $49.00 per year.
- Premium Plan: $69.00 per year.
- Free Plan: Available.

Gotalk.ai
Gotalk.ai is an advanced AI voice generator that uses deep learning algorithms to convert text into natural, human-like speech. It is designed to simplify the voiceover creation process for content creators, marketers, and professionals in various industries, offering an intuitive interface and extensive customization options. This tool enables high-quality voiceover production without the need for expensive equipment or professional voice artists.


Features
- AI Voice Generation: Utilizes deep learning technology to produce lifelike voiceovers from text.
- Customization Options: Allows users to adjust tone, pitch, accent, and pacing for personalized voiceovers.
- User-Friendly Interface: Simplifies the creation and editing process for those with minimal technical expertise.
- Integration with Media: Supports easy integration of voiceovers with videos, audio files, and images.
- Cost-Effective: Provides an affordable alternative to traditional voice recording methods.
Pricing
- Creator: $24.54
- Pro: $58.11
- Enterprise: $122.68
- Free Plan: Available.

Listnr
Listnr is a cutting-edge generative AI software that transforms written content into high-quality audio. This AI-powered platform enables businesses to create engaging audio content for a variety of purposes, including podcasts, audiobooks, advertisements, and corporate communications. Using natural language processing (NLP) and machine learning models, Listnr analyzes the text you input and generates realistic voiceovers with different accents, tones, and speaking styles. Whether you need a professional-sounding narrator for an instructional video, a creative voice for a podcast, or an energetic voiceover for an advertisement, Listnr offers a range of customizable voice options.

Features
- Text-to-Speech (TTS) Technology: Listnr AI offers advanced TTS capabilities, providing over 1000 lifelike and natural-sounding voice outputs in multiple languages and accents. This makes it suitable for a wide range of applications, including podcasts, audiobooks, and more.
- Customizable Voice Options: You can choose from various voices and adjust parameters such as speed, pitch, and volume to better suit their needs. This level of customization ensures that the voice output matches the desired tone and style.
- Multilingual Support: Listnr AI supports 142 languages, making it accessible for global users. This feature is particularly useful for businesses and content creators targeting international audiences.
- API Access: Developers can leverage Listnr AI’s API to embed TTS functionalities into their applications, enhancing their products with high-quality voice synthesis.
- Voice Cloning: Listnr AI offers voice cloning capabilities, enabling you to create a synthetic voice that closely mimics a specific person. This can be used for personalized content and branding.
Pricing
- Individual: $190.00 per year.
- Solo: $390.00 per year.
- Agency: $990.00 per year.

Resemble
Resemble AI is an advanced voice synthesis platform designed to create realistic and scalable voice content for various applications. This tool leverages cutting-edge AI technology to clone voices with a high degree of accuracy, making it possible to generate lifelike audio outputs from text inputs. Resemble AI is particularly useful for developers and creators who need to produce voiceovers or digital speech for games, virtual assistants, audiobooks, and other multimedia projects.

Features
- Custom Voice Creation: Resemble AI has a special feature where you can make custom AI voices. This means you can create voices that sound like real people, maybe even like you or someone you know.
- Real-time Voice Cloning: Resemble AI’s real-time voice cloning is a standout feature. It lets you clone voices quickly, making it easy to create speech that sounds like a real person. This is great for projects that need fast voiceovers.
- Emotion and Intonation Control: Resemble AI offers a unique feature where you can control the emotion and intonation of the voice it creates. This means you can make the voice sound happy, sad, excited, or any other way you want.
- Scalable Solution: Resemble AI is a flexible and scalable tool, which means it works well for both single users and big companies. This is great because it can handle small personal projects as well as large business tasks.
- Voice Talent Marketplace: Resemble AI offers a unique feature called the Voice Talent Marketplace. This marketplace lets users pick from a range of professional voice talents for their projects.
Pricing
- Starter: $5.00 per month.
- Creator: $19.00 per month.
- Professional: $99.00 per month.
- Scale: $299.00 per month.
- Business: $699.00 per month.
- Enterprise: Contact Team.
- Free Plan: Available.



Uberduck
Uberduck is an innovative text-to-speech tool that stands out in the digital landscape for its unique capabilities and extensive range of voice options. This advanced platform allows users to convert written text into spoken words using a variety of voices, ranging from celebrity imitations to original character voices. What sets Uberduck apart is its integration with artificial intelligence, enabling it to deliver not just clear and natural-sounding audio outputs, but also to capture nuanced vocal expressions that add a layer of realism rarely found in standard text-to-speech applications.
Features
- Celebrity Voice Clones: Impersonate iconic figures — from Morgan Freeman narrating your bedtime story to Barack Obama delivering a motivational speech. While not perfect replicas, the resemblance is uncanny, adding a layer of fun and familiarity to your creations.
- Custom Voice Creation: Craft your own voice from scratch! Fine-tune pitch, timbre, and emotion to bring your vision to life. Imagine crafting a whimsical fairy’s voice, or a gruff pirate captain’s growl — the possibilities are endless.
- AI-Generated Scripts: Stuck for dialogue? Let the AI craft scripts based on your chosen voice and context. This handy feature helps overcome writer’s block and injects unexpected twists into your narratives.
- Advanced Audio Editing: Polish your audio with tools like filters, effects, and background music. Seamlessly integrate your AI-generated voices into existing audio for a professional touch.
- Accessible and User-Friendly: Uberduck’s interface is intuitive and visually appealing, making it a breeze to even for novices. Whether you’re a seasoned creator or a curious beginner, you’ll be crafting compelling voices in no time.
Pricing
- Starter: $2.00 per month.
- Creator: $5.00 per month.
- Pro: $30.00 per month.
- Enterprise: Contact Team.
- Free Plan: Available.

Wellsaidlabs
WellSaid Labs is an innovative tool designed to transform text into lifelike, natural-sounding speech using advanced AI technology. This platform is ideal for professionals in various sectors, including e-learning, media production, and corporate training, who require high-quality voiceovers without the need for professional voice actors. WellSaid Labs offers a diverse range of voice avatars, each tailored to deliver distinct vocal styles and accents, ensuring that users can find the perfect match for their specific project needs. The tool is incredibly user-friendly, allowing users to input their text and select their preferred voice with ease.

Features
- Realistic voice synthesis: Create natural-sounding audio using AI-generated voices tailored for various content types.
- Extensive voice library: Access a diverse range of voices to find the perfect match for your project’s needs.
- Easy integration: Seamlessly incorporate synthesized voices into your applications with straightforward API access.
- Custom voice creation: Personalize your audio content by developing unique voices that represent your brand’s identity.
- Scalable solutions: Efficiently scale your audio production to meet demand without compromising on quality.
- Real-time processing: Generate and deploy voice content quickly with minimal latency, enhancing user experience.
Pricing
- Creative: $89.10 per month.
- Business: $179.10 per month.
- Enterprise: Contact Team.
- Free Plan: Available.
